The divergence of the Q-value estimation has been a prominent issue offline reinforcement learning (offline RL), where the agent has no access to real dynamics. Traditional beliefs attribute this instability to querying out-of-distribution actions when bootstrapping value targets. Though this issue can be alleviated with policy constraints or conservative Q estimation, a theoretical understanding of the underlying mechanism causing the divergence has been absent. In this work, we aim to thoroughly comprehend this mechanism and attain an improved solution. We first identify a fundamental pattern, self-excitation, as the primary cause of Q-value estimation divergence in offline RL. Then, we propose a novel Self-Excite Eigenvalue Measure (SEEM) metric based on Neural Tangent Kernel (NTK) to measure the evolving property of Q-network at training, which provides an intriguing explanation of the emergence of divergence. For the first time, our theory can reliably decide whether the training will diverge at an early stage, and even predict the order of the growth for the estimated Q-value, the model's norm, and the crashing step when an SGD optimizer is used. The experiments demonstrate perfect alignment with this theoretic analysis. Building on our insights, we propose to resolve divergence from a novel perspective, namely improving the model's architecture for better extrapolating behavior. Through extensive empirical studies, we identify LayerNorm as a good solution to effectively avoid divergence without introducing detrimental bias, leading to superior performance. Experimental results prove that it can still work in some most challenging settings, i.e. using only 1% transitions of the dataset, where all previous methods fail. Moreover, it can be easily plugged into modern offline RL methods and achieve SOTA results on many challenging tasks. We also give unique insights into its effectiveness.
In our paper, we theoretically prove that Q-value divergence happens when the maximal eigenvalue of the following matrix \(A_t\) (namely SEEM) is greater to 0:
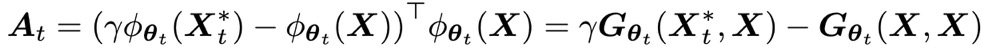
The intuitive interpretation for SEEM is as below: If SEEM is positive, the generalization bond between \(Q_\theta(X)\) and \(Q_\theta(X^*_t)\) is strong. When updating the value of \(Q_\theta(X)\) towards \(r+\gamma Q_\theta(X^*)\), due to strong generalization of the neural network, the Q-value iteration inadvertently makes \(Q_\theta(X^*)\) increase even more than the increment of \(Q_\theta(X)\). Consequently, the TD error \(r+\gamma Q_\theta(X^*) - Q_\theta(X)\) expands instead of reducing, due to the target value moving away faster than predicted value, which encourages the above procedure to repeat. This forms a positive feedback loop and causes self-excitation. Such mirage-like property causes the model’s parameter and its prediction value to diverge.
we can monitor SEEM value to know whether the training will diverge.

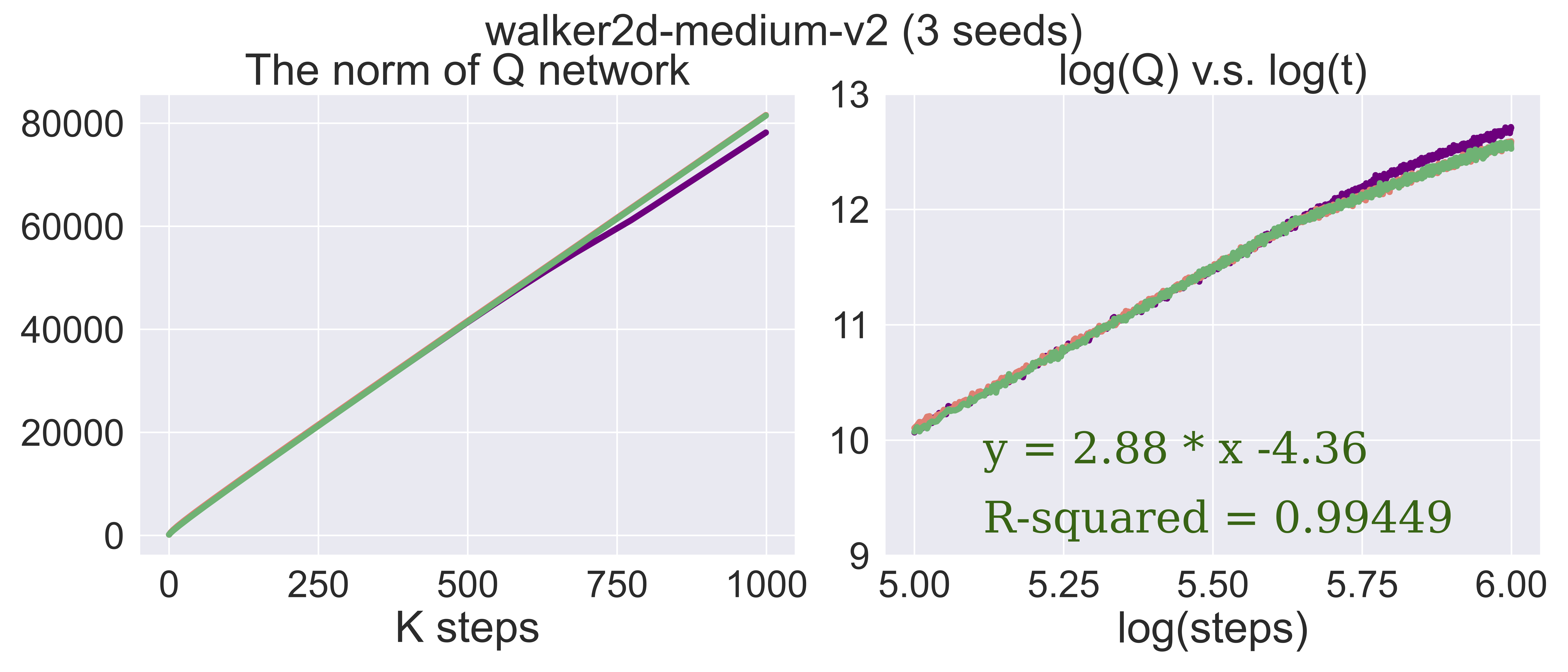
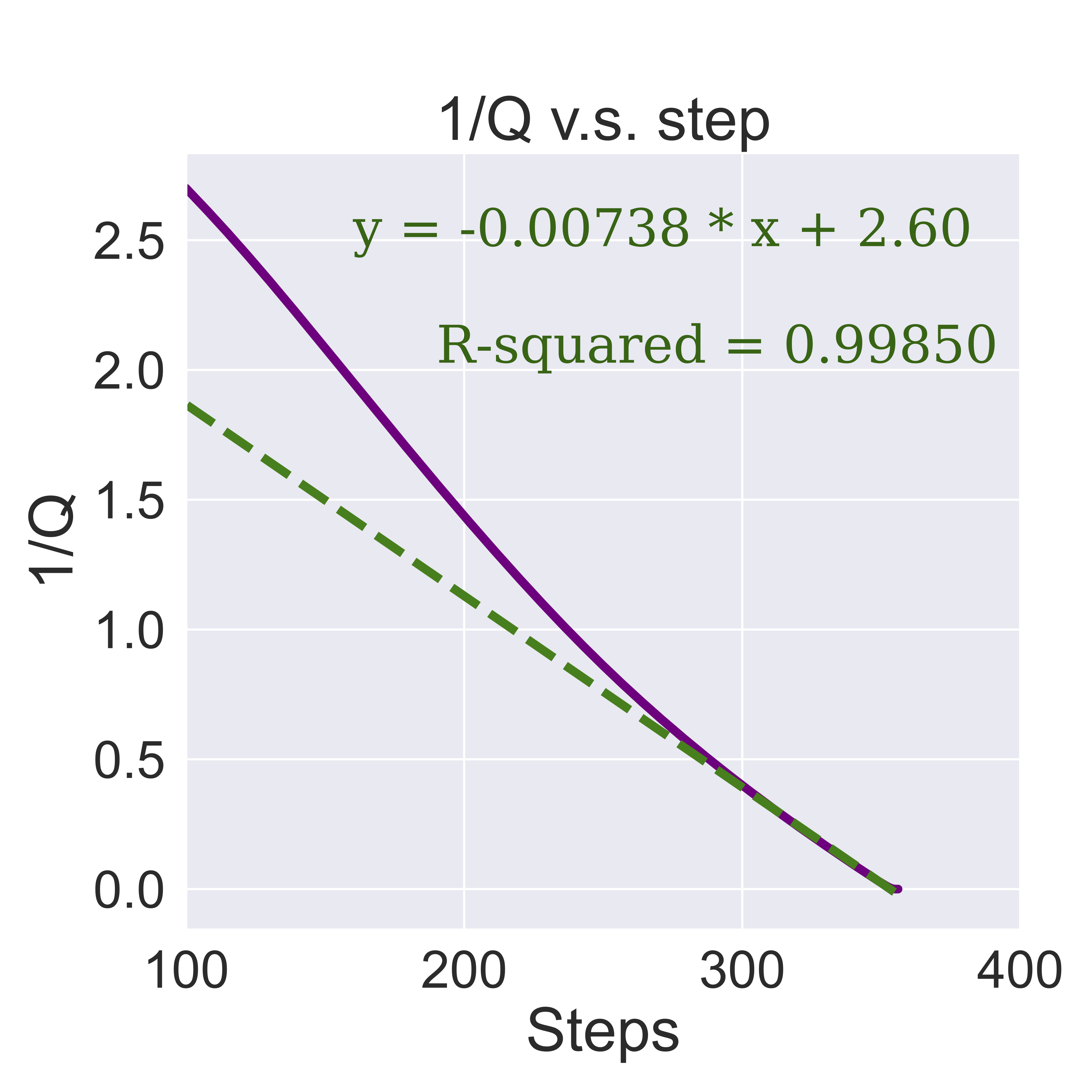
Except predicting whether the training will diverge, SEEM is able to predict the order of the growth for the estimated Q-value and the model's norm:
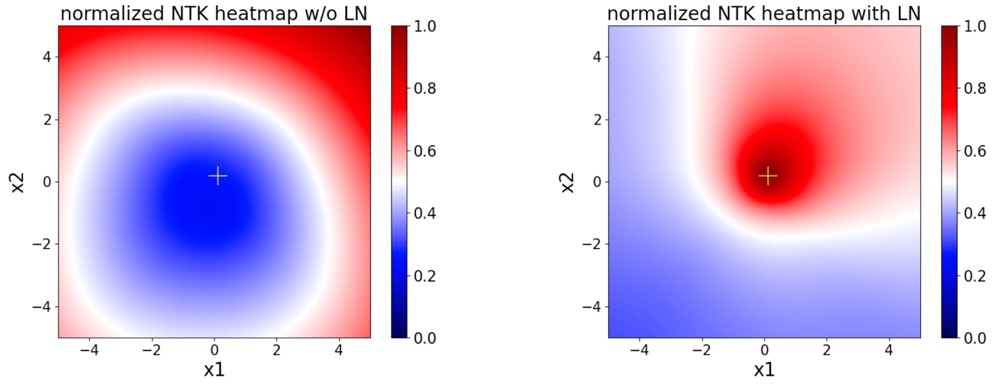
In essence, a large SEEM value arises from the improper link between the dataset inputs and out-of-distribution data points. The MLP without normalization demonstrates abnormal behavior that the value predictions of the dataset sample and extreme points at the boundary have large NTK value and exhibit a strange but strong correlation. This indicates an intriguing yet relatively under-explored approach to avoid divergence: regularizing the model’s generalization on out-of-distribution predictions.
Therefore, a simple method to accomplish this would be to insert a LayerNorm prior to each non-linear activation.
We provide theoretical justification explaining why LayerNorm results in a lower SEEM value in the supplementary material of our paper.

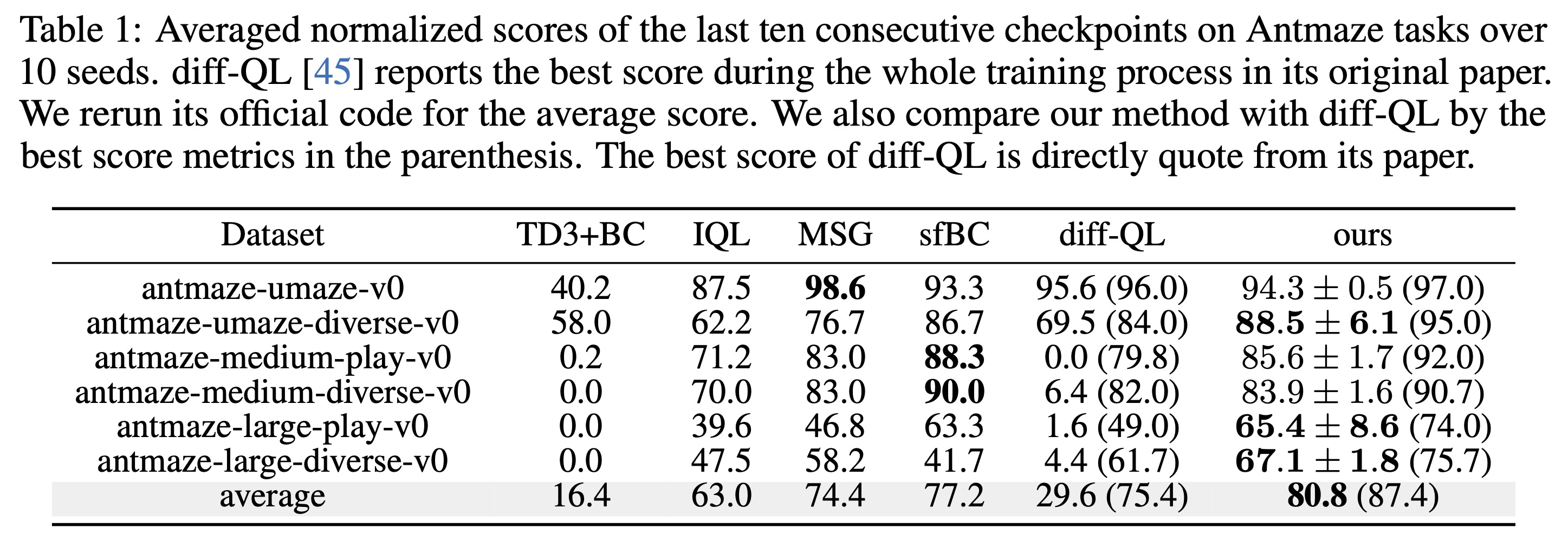
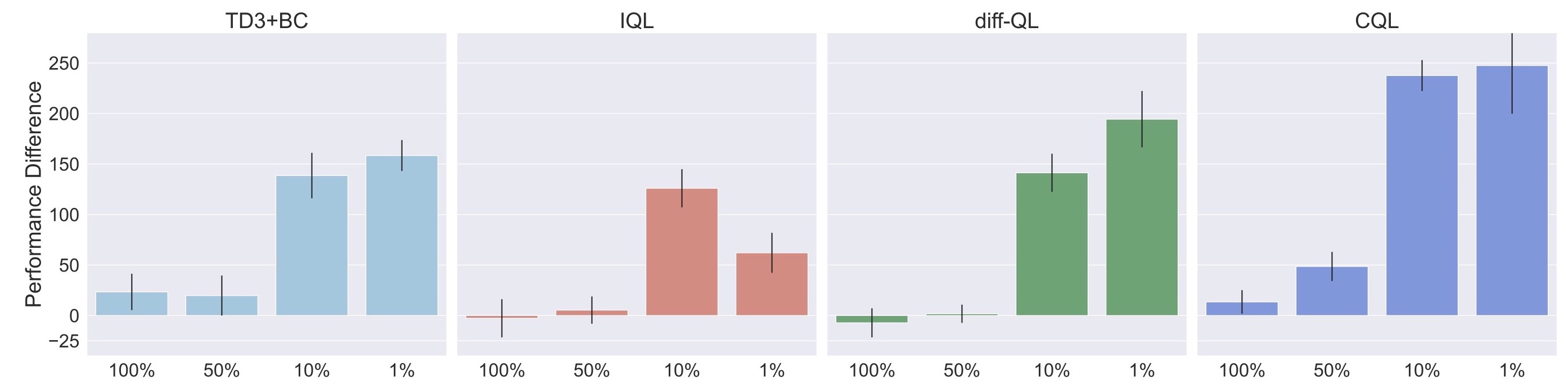
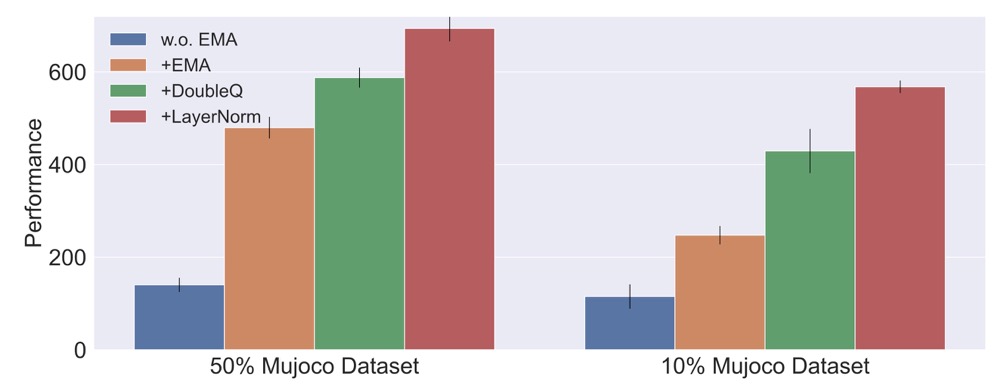

In this paper, we propose an eigenvalue measure called SEEM to reliably detect and predict the divergence. Based on SEEM, we proposed an orthogonal perspective other than policy constraint to avoid divergence, by using LayerNorm to regularize the generalization of the MLP neural network. Moreover, the SEEM metric can serve as an indicator, guiding future works toward further engineering that may yield adjustments with even better performance than the simple LayerNorm. We hope that our work can provide a new perspective for the community to understand and resolve the divergence issue in offline RL. Anyone interested in this topic is welcome to discuss with us (yueyang22f at gmail dot com).
@proceedings{yue2023understanding,
title ={Understanding, Predicting and Better Resolving Q-Value Divergence in Offline-RL},
author = {Yang Yue and Rui Lu and Bingyi Kang and Shiji Song and Gao Huang},
booktitle = {NeurIPS},
year = {2023},
}